PADIC
PADIC is a Parallel Arabic DIalect Corpus PADIC is composed of about 6400 sentences of dialects from both the Maghreb and the Middle-East. Each dialect has been aligned with Modern Standard Arabic (MSA). PADIC includes four dialects from Maghreb: two from Algeria, one from Tunisia, one from Morocco and two dialects from the Middle- East (Syria and Palestine). PADIC has been built from scratch by the members of SMarT research: Salima Harrat, Karima Meftouh and K. Smaïli and with the participation of M. Abbas. The translation of Tunisian has been done by Salma Jamoussi, Moroccan by Samia Haddouchi, Palestinian by Motaz Saad and Syrian by Charif Alchieekh Haydar.
Any use of PADIC shall include the following acknowledgement: “Programme material SMarT” and will use the following article for referencing it:
- Meftouh, S. Harrat, M. Abbas, S. Jamoussi, and K. Smaïli, “Machine Translation Experiments on PADIC: A Parallel Arabic DIalect Corpus”, PACLIC29, Shanghai, 2015
- Meftouh, S Harrat, Kamel Smaïli, “PADIC: extension and new experiments” 7th International Conference on Advanced Technologies ICAT, Apr 2018, Antalya, Turkey. 7th International Conference on Advanced Technologies, 2018
Note that in the first version of PADIC and in this last paper, the Moroccan dialect was not available and not mentioned. Two Moroccan from Casablanca and Rabat included the Moroccan part. Consequently, we recommend you to reference the above article.
Download: A Parallel Arabic DIalect Corpus
CALYOU is a Comparable Spoken Algerian Corpus Harvested from YouTube
We developed an approach based on word embedding that permits to align the best comment written in Algerian dialect with a comment written in Latin script. That means that an Arabic dialect sentence could be aligned with French or Arabizi sentence. A sample is given below.
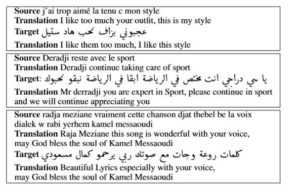
Karima Abidi, Mohamed Amine Menacer, Kamel Smaili “CALYOU: A Comparable Spoken Algerian Corpus Harvested from YouTube”, 8th Annual Conference of the International Communication Association (Interspeech), Aug 2017, Stockholm, Sweden.
Download: CALYOU (Comparable Spoken Algerian Corpus harvested from YOUtube)
Lexicon of variable forms of Algerian words
This resource gathers the words with their different writing possibilities (orthographic variability). This variability is the main characteristic of the Arabic dialects especially those used in social networks. The orthographic variability is due to the lack of standardization of writing, the use of Arabizi (writing Arabic words with Latin characters) and the lack of grammatical rules for the dialects. The lexicon was built automatically using word embedding approach. Each entry is composed by a word and its different writing forms. This resource can be very useful in many applications of natural language processing. Some examples of the dictionary entries are given below.
Karima Abidi, Kamel Smaïli.” An Automatic Learning of an Algerian Dialect Lexicon by using Multilingual Word Embeddings”. 11th edition of the Language Resources and Evaluation Conference, LREC 2018, May 2018, Miyazaki, Japan.
| Entry | Forms |
| يحفدك | yahafdak yahfdek yahfedk yahefdek yahafdeek yahfdak yahafdek yahefdak yehafdak yahafadak |
| يرحمك | yr7mk yr7mak yrhamak yarhamek yarhemak yarhamk yarhmek yr7mek yere7mek yarhamak yarhemek yrhmk yar7mak yarhmak yer7makyarahmak yar7mek yarahmk yerhemek yarahmek yerehmek yerhamek yar7mik yare7mek yerhamak yer7mek yerehemek yarhmeke rahimaka yrahmek yrahmak irahmak irhmak irahmek irhmk yra7mk yerahmak yrehmak yera7mak yerehmkyrhmak yera7mek yrehmek yara7mak yarehmek yara7mek yerahmeke yrhmek yarehmak yarhmk yerhmk yarhmeek yra7mak yerahmek ir7mak yra7mek yrahmk yarhamoka yrehmk yar7mk yerhmk ira7mak irehmek yerhmek yarahemek yerahmk yerhmek yrhmek yerahmak |
| فلم | film filme |
| Mister | مستر ميستر |
| Mansotich | مانسوطيش منسطيش منسوطييش مانصوتيش مانسوطييش ماانسووطيش منسوطيش مانسوطيوش مانصوطوش منصوطيش |
Demos
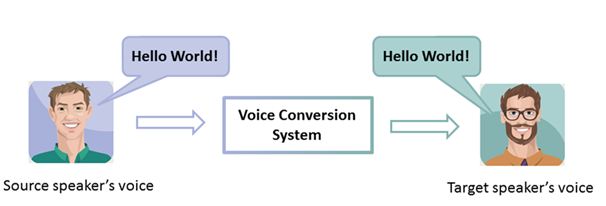 Voice conversion is an important problem in audio signal processing. The goal of voice conversion consists in transforming the speech signal of a source speaker in such a way that that it sounds as if it had been uttered by a target speaker while preserving the same linguistic content of the source original signal. We propose a novel methodology for designing the relationship between two sets of spectral envelopes. Our systems perform by: 1) cascading Deep Neural Networks and Gaussian Mixture Model to construct DNN-GMM and GMM-DNN-GMM predictors in order to find a global mapping relationship between the cepstral vocal tract vectors of the two speakers; 2) using a new spectral synthesis process with excitation and phase extracted from the target training space encoded as a KD-tree. We present in this demo samples of voice conversion outputs from male and female source speakers.
Voice conversion is an important problem in audio signal processing. The goal of voice conversion consists in transforming the speech signal of a source speaker in such a way that that it sounds as if it had been uttered by a target speaker while preserving the same linguistic content of the source original signal. We propose a novel methodology for designing the relationship between two sets of spectral envelopes. Our systems perform by: 1) cascading Deep Neural Networks and Gaussian Mixture Model to construct DNN-GMM and GMM-DNN-GMM predictors in order to find a global mapping relationship between the cepstral vocal tract vectors of the two speakers; 2) using a new spectral synthesis process with excitation and phase extracted from the target training space encoded as a KD-tree. We present in this demo samples of voice conversion outputs from male and female source speakers.
| Source Speaker (CLB) ‘s Original Utterance
|
Target Speaker (BDL)’s ;
|
|---|---|
|
Methods |
GMM |
DNN |
GMM-DNN-GMM |
DNN-GMM |
|
Source Speaker (CLB)’s Converted Utterance;
|
|---|
|
Source Speaker (BDL) ‘s Original Utterance
|
Target Speaker (RMS)’s ;
|
|---|---|
|
|
|
|
Methods
|
GMM
|
DNN
|
GMM-DNN-GMM
|
DNN-GMM
|
|
Source Speaker (BDL)’s Converted Utterance;
|
|
|
|
|
|---|
|
Source Speaker (SLT)’s Original Utterance;
|
Target Speaker (CLB)’s
|
|---|---|
|
|
|
|
Methods
|
GMM
|
DNN
|
GMM-DNN-GMM
|
DNN-GMM
|
|
Source Speaker (SLT)’s Converted Utterance;
|
|
|
|
|
|---|
|
Source Speaker (RMS)’s Original Utterance
|
Target Speaker (SLT)’s
|
|---|---|
|
|
|
|
Methods
|
GMM
|
DNN
|
GMM-DNN-GMM
|
DNN-GMM
|
|
Source Speaker (RMS)’s Converted Utterance;
|
|
|
|
|
|---|
 The method adopted in this paper for enhancing esophageal voice consists in using a combination of a voice conversion technique and a time dilation algorithm. The proposed system extracts and separates excitation and vocal tract parameters using a speech parameterization process (Fourier cepstra). Next, a Deep Neural Network DNN is used as a nonlinear mapping function for vocal tract vector transformation, and then the converted vectors are used to determine a realistic excitation and phase from the target training space using a frame selection algorithm. However, in order to preserve laryngectomees speaker identity we use the source vocal tract features and propose to apply on them a time dilation algorithm to reduce the unpleasant esophageal noises. Finally the converted speech is resynthesized using the dilated source vocal tract parameters and the predicted excitation and phase. An experimental comparison study has been realized for reviewing the changes in speech quality and intelligibility of the different enhanced samples obtained. Experimental results demonstrate that the proposed method yields great improvements in intelligibility and naturalness of the converted esophageal stimuli. Results of voice conversion evaluated using objective and subjective experiments, validate the proposed approach.
Table below exhibits some examples obtained by the proposed Voice Enhancement Technology. The “Source Speech” column indicates examples of utterances pronounced by two laryngectomees. The next four columns, “GMM”, “DNN”, “DNN_Src” and “DNN_Srcdilated” concern the resynthesized results using our Voice conversion technology.
The method adopted in this paper for enhancing esophageal voice consists in using a combination of a voice conversion technique and a time dilation algorithm. The proposed system extracts and separates excitation and vocal tract parameters using a speech parameterization process (Fourier cepstra). Next, a Deep Neural Network DNN is used as a nonlinear mapping function for vocal tract vector transformation, and then the converted vectors are used to determine a realistic excitation and phase from the target training space using a frame selection algorithm. However, in order to preserve laryngectomees speaker identity we use the source vocal tract features and propose to apply on them a time dilation algorithm to reduce the unpleasant esophageal noises. Finally the converted speech is resynthesized using the dilated source vocal tract parameters and the predicted excitation and phase. An experimental comparison study has been realized for reviewing the changes in speech quality and intelligibility of the different enhanced samples obtained. Experimental results demonstrate that the proposed method yields great improvements in intelligibility and naturalness of the converted esophageal stimuli. Results of voice conversion evaluated using objective and subjective experiments, validate the proposed approach.
Table below exhibits some examples obtained by the proposed Voice Enhancement Technology. The “Source Speech” column indicates examples of utterances pronounced by two laryngectomees. The next four columns, “GMM”, “DNN”, “DNN_Src” and “DNN_Srcdilated” concern the resynthesized results using our Voice conversion technology.
|
Source Speech |
GMM |
DNN |
DNN_Src |
DNN_Srcdilated |